FULL-STACK WEB APP | 2025
PopChoice
An AI-powered group movie recommender — each person submits their preferences, and a RAG pipeline semantically matches them against a vector database of films before GPT selects the best picks and explains why.
OVERVIEW
IMPLEMENTATION
TECH STACK
Language
JavaScript
Build
Vite
AI
OpenAI API (Embeddings + GPT)
RAG
LangChain (Text Splitters)
Database
Supabase
Backend
Cloudflare Workers
APIs
OMDB API
Deployment
Cloudflare Pages
FEATURES
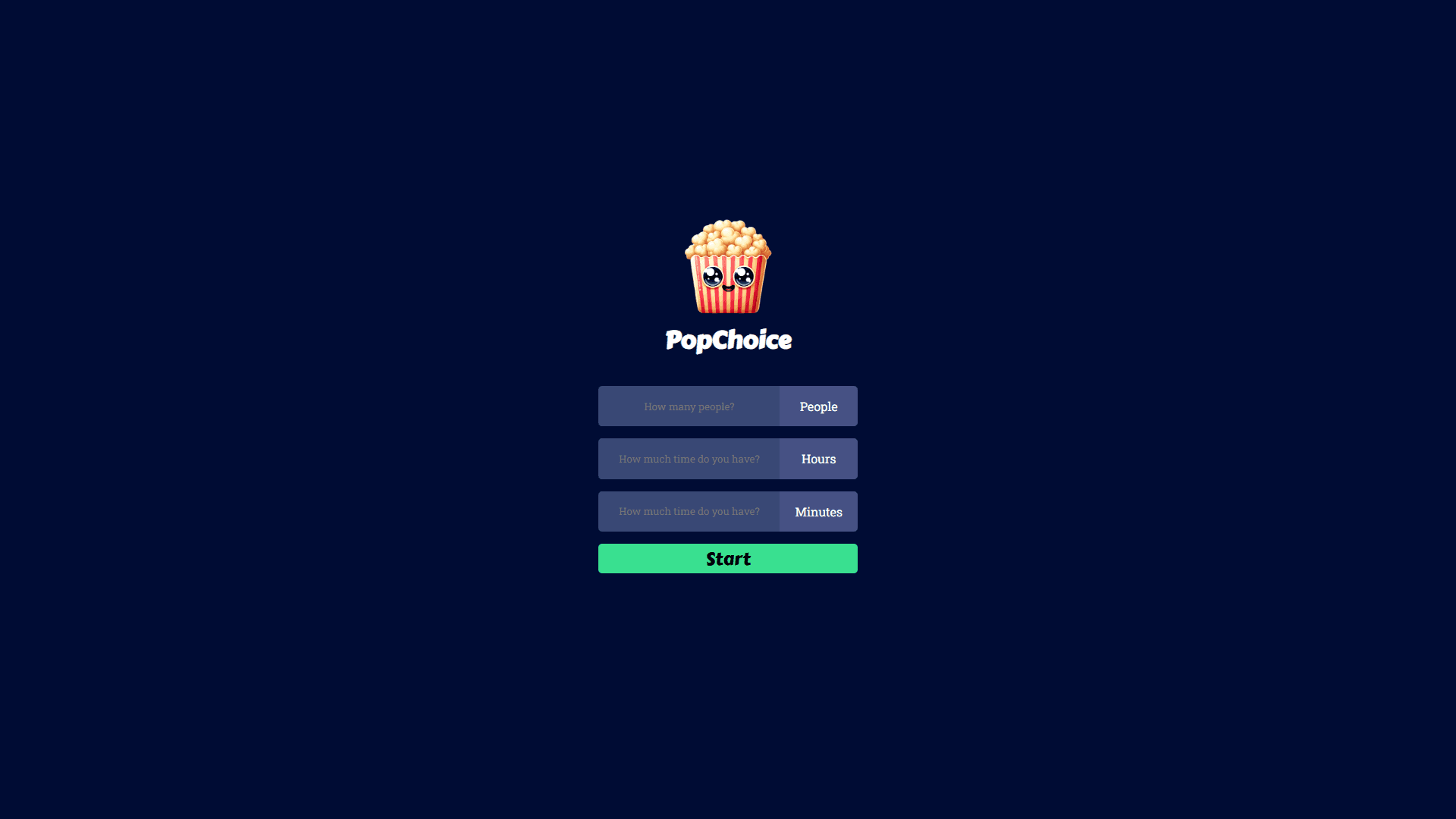
Group preference collection — time availability and individual tastes per member
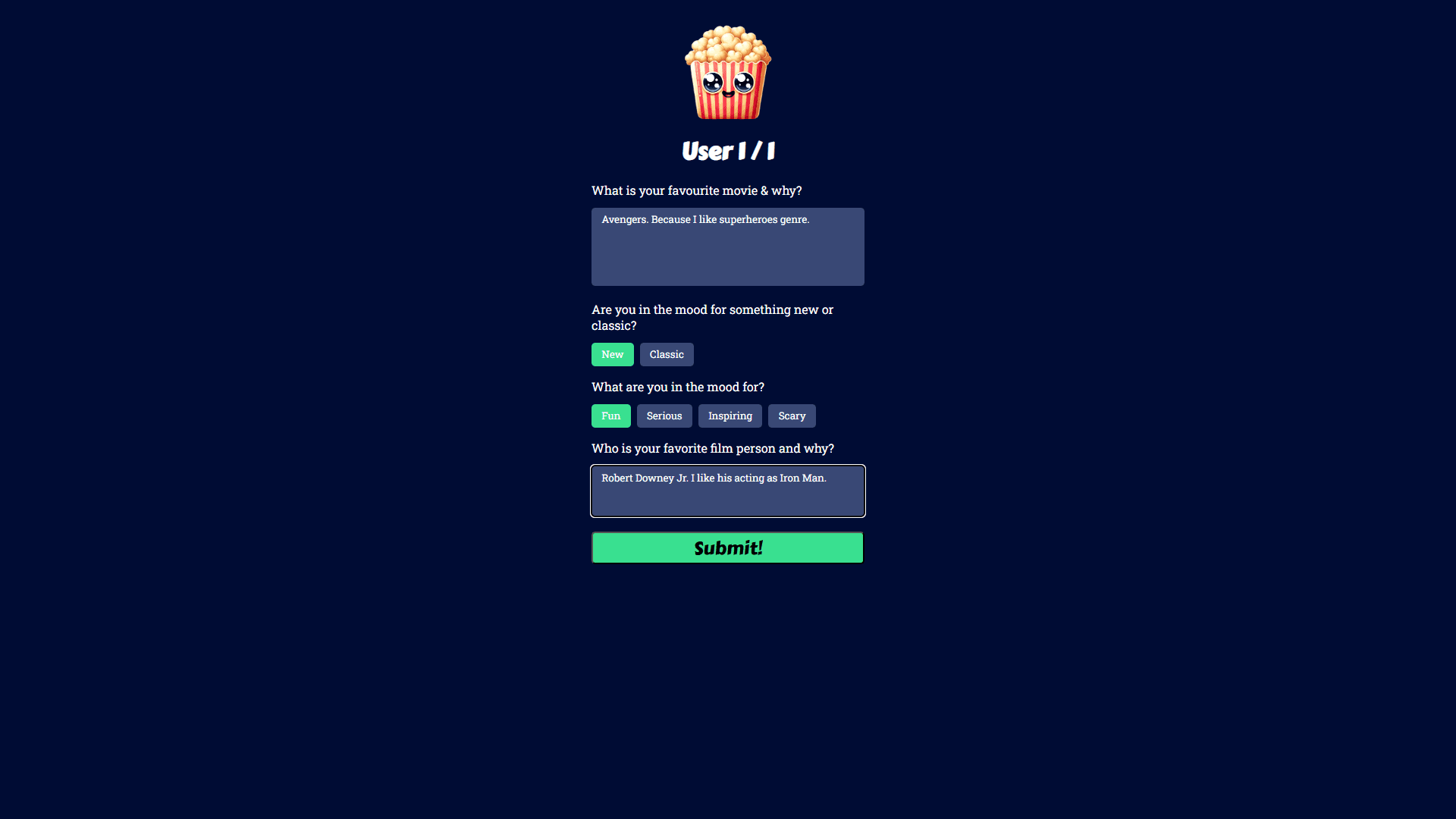
Per-member preference survey — favourite movie, mood, and preferred actor or director
RAG-powered recommendation — semantic vector search over a Supabase pgvector movie database
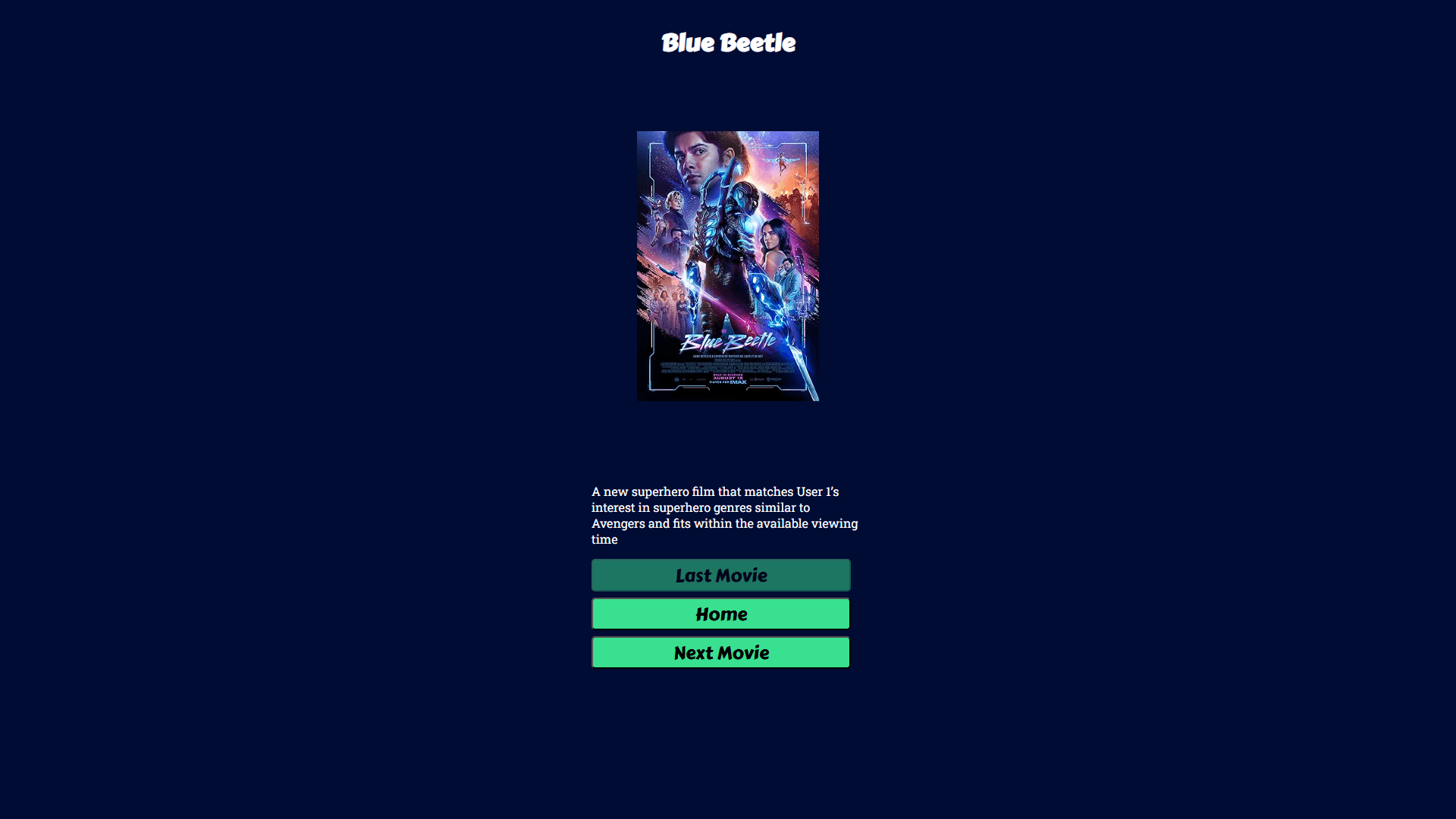
GPT-generated explanation for each recommendation
Movie posters fetched and displayed via OMDB API
Interactive recommendation carousel with next and previous navigation
Cloudflare Worker backend keeping all API keys off the client
CHALLENGES & SOLUTIONS
API key exposure in client-side code
Moved all API calls — OpenAI embeddings, Supabase vector queries, and GPT inference — behind a Cloudflare Worker, so credentials never leave the server. The frontend makes a single POST to the worker endpoint and receives the finished recommendations.
Keyword search being insufficient for preference matching
Implemented RAG using OpenAI's text embedding model and Supabase pgvector. User preferences are converted to a vector embedding at query time and matched against pre-embedded movie descriptions via cosine similarity — retrieving semantically relevant films even when no exact keywords overlap.
Aggregating preferences from multiple users into a single query
Collected each group member's preferences individually through a multi-step survey, then serialised all responses into a single natural language query combining the group's tastes and available watch time. This single query drives the full RAG retrieval pipeline.
Unreliable GPT output format breaking carousel parsing
Enforced a structured delimiter format in the GPT prompt — `movie_name1#reason1#movie_name2#reason2...` — making the client-side parsing deterministic and resilient to natural language variation in the model's output.